
Over the past few weeks, I had noticed errors my zfs storage pool. The errors were no big deal, errors happen. ZFS is fantastic and detects and corrects them automatically. However, it was happening often enough I decided to I needed to look into if one of the HDDs was failing. Sure enough, the errors were coming from a 6TB WD Red that I have had in service about three years now. I ordered a new 6TB drive or replace it with, which arrived Tuesday. I popped the drive into one of my bays and started a zfs resilver operation.
sudo zpool offline storage_pool_name failing_hdd_name
sudo zpool replace storage_pool_name failing_hdd_name new_hdd_name
The resilver operation was off, and it estimated that it was going to take 36 hours. Later that night I checked into my arrays rebuild progress, and it had only progressed .05%…
root@pve:/storage/docker/zabbix# zpool status
pool: storage
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Tue Mar 20 18:10:30 2018
33.9G scanned out of 68.0T at 3.74M/s, (scan is slow, no estimated time)
1.87G resilvered, 0.05% done
The replacement drive I had ordered was just this cheap Seagate. I don’t think I had done proper research and this was not a drive suited for large arrays. That or it was a bad drive. I decided to return and pay an extra $30 for a WD Red. Even though the WD drive has less cache, it gave me much better performance and a better warranty. So this drive arrived Friday. I canceled the zfs resilver and then started it over with the new WD drive.
sudo zpool offline storage_pool_name slow_seagate_name
sudo zpool replace storage_pool_name failing_hdd_name new_WDhdd_name
This time the rebuild progressed at much faster speeds. It ranged from 250M/s to 1000M/s. I decided that while I was on my server, I would do some other update maintenance. I updated my packages, checked my backups, and cleaned up my home directory. I decided to reboot the server since I hadn’t in a few weeks. This reboot was what ruined my day. My server normally takes about 6-7 minutes to do a reboot, most of this time is on random splash screens for my HBA (raid cards). After 10 minutes, I still couldn’t ssh into my server. I was beginning to worry, so I launched my IPMI and a remote console viewer. This screen greeted me.
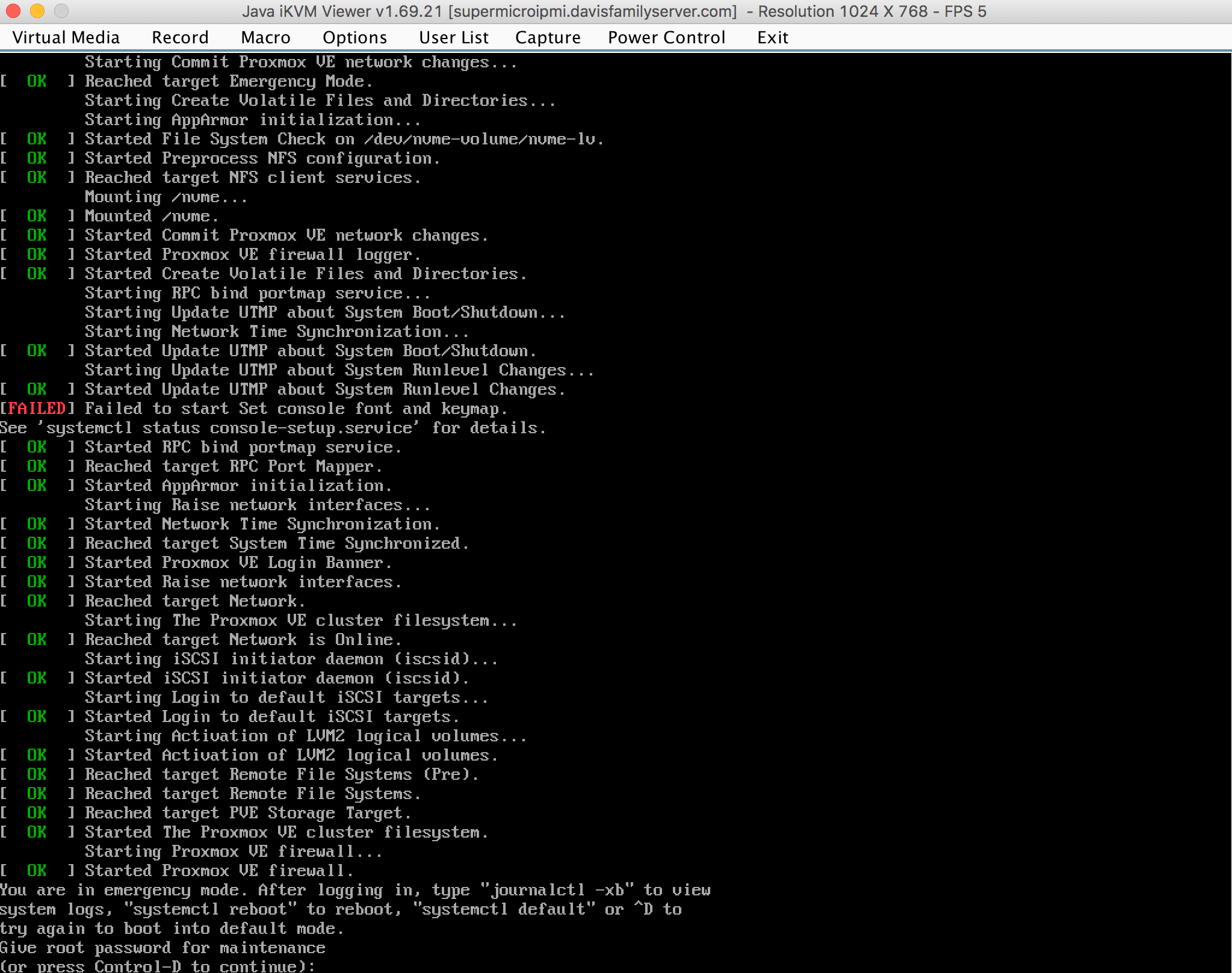
YOU ARE IN EMERGENCY MODE
Well, $%#^! I had never seen this screen before and googled it and found it is an error screen specific to Proxmox, my OS. I pressed control-d a few times in hopes that the screen was just a fluke and that all was still well. That didn’t work. I rebooted the server again for giggles to see if it would help, it didn’t. I was still stuck on this same screen. I then just typed in my root password to bypass it. I was happy to see that I could still use my server and proceeded to manually start up docker and other services so that my family members could still access Plex (Got to keep that up time yo). I then outputted the journalctl -xb command to a text file and copied that to my laptop
jouarnalctl -xb > error.txt
scp error.txt nathan@macbookIP:/Users/nathan/downloads
I opened the error file in atom and started to flip through it. It was 7000 lines long and very verbose. I stopped and started to look online to what went wrong when other people got this error. I found this forum post on Proxmox’s site, but it didn’t seem to have a resolution, and none of the suggestions worked for me. I decided to stop debugging it since it was a Friday and all my critical services were working.
After a nights sleep, I reapproached the problem. I started digging through the error file by searching for the word “error.” There were a lot of errors for the docker service starting and other things. I noted a few errors for btrfs mounting a drive /dev/sdt. This made me think, wait why am I mounting drives by their disk assignment, those can change. Then searched for fstab errors. I found this
Mar 24 11:09:01 pve systemd[1]: Mounting /ssd...
-- Subject: Unit ssd.mount has begun start-up
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Unit ssd.mount has begun starting up.
Mar 24 11:09:01 pve systemd[1]: Stopped Emergency Shell.
-- Subject: Unit emergency.service has finished shutting down
-- Defined-By: systemd
-- Support: https://www.debian.org/support
--
-- Unit emergency.service has finished shutting down.
Mar 24 11:09:01 pve systemd[1]: ssd.mount: Mount process exited, code=exited status=32
Mar 24 11:09:01 pve systemd[1]: Failed to mount /ssd.
-- Subject: Unit ssd.mount has failed
-- Defined-By: systemd
Finally, I opened my /etc/fstab file. Sure enough, like an idiot, I had mounted the SSD with /dev/sds instead of by a never changing id. Looking around the ssd’s disk assignment had changed from /dev/sds to /dev/sdt. /dev/sds was now the satadom ext4 boot drive. This was all my problem! I edited my fstab to mount by id like
/dev/disk/by-id/unique-id /ssd btrfs defaults 0 1
And then rebooted my server. Emergency mode is gone, and I was greeted by a normal boot screen. Lesson learned, never mount devices by an id that can change.
Lesson learned, never mount devices by an id that can change